The Problem
Even though everyone is a pedestrian, we can't use data to answer simple questions like, "Can I get there from here?" This is because the data we could use to ask these questions has never been collected! And when data does exist, it's published in non-standardized formats that are unsuitable for analysis.

Pedestrian diversity means detailed data
Pedestrians have a wide variety of needs and preferences. For example, a given wheelchair user may need to avoid steep hills whereas another will attempt any hill. Therefore, data on pedestrian spaces must be detailed and specific: instead of labeling a path 'wheelchair accessible' in advance, we need to store data on its steepness and interpret it based on rules like 'no steepness greater than 8 percent'.
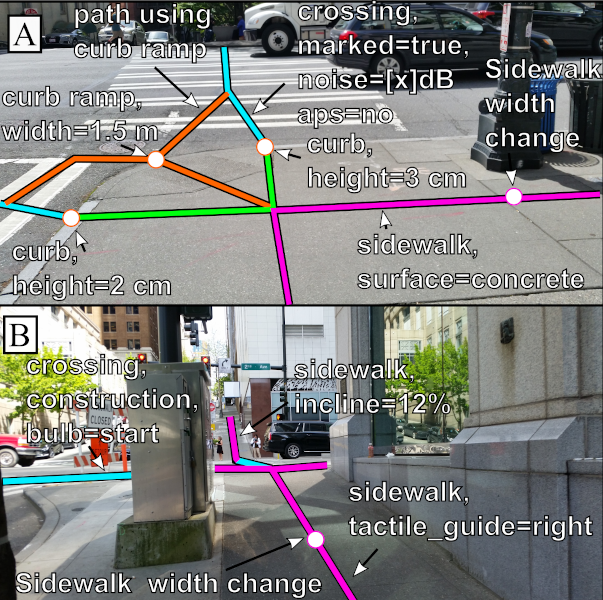
Enter OpenSidewalks
OpenSidewalks seeks to make pedestrian ways, like sidewalks, first class members of an open, routable transportation network from which we can ask a variety of important questions. This means collecting a connected network of path types with detailed attributes like width, surface composition, steepness, and shared traffic.

What do we do?
Because pedestrian data has usually been so neglected, the OpenSidewalks project has to tackle many problems at once. We define (or help define) data schemas, create tools to organize and track data collection efforts, and create applications that consume OpenSidewalks data to demonstrate usefulness and ensure accuracy.
Team
OpenSidewalks is led by the Taskar Center for Accessible Technology (TCAT) at the University of Washington, whose mission is to develop and deploy technologies that improve quality of life for people with disabilities.
The University of Washington's eScience Institute provided an opportunity for the OpenSidewalks project to develop as a part of their Data Science for Social Good program that took place in the summer of 2016. Through this program, an interdisciplinary team of project leads, data scientists, and student fellows spent 10 weeks pushing the project forward.
Project Leads
Nick Bolten
Anat Caspi
Partners
Header photo by Jake Stimpson